Data Processing API (DP API)
DP API is for running jobs via job configurations. Job configurations are configurations of models that the user would like to run. Models are stored in Azure Container Registries.
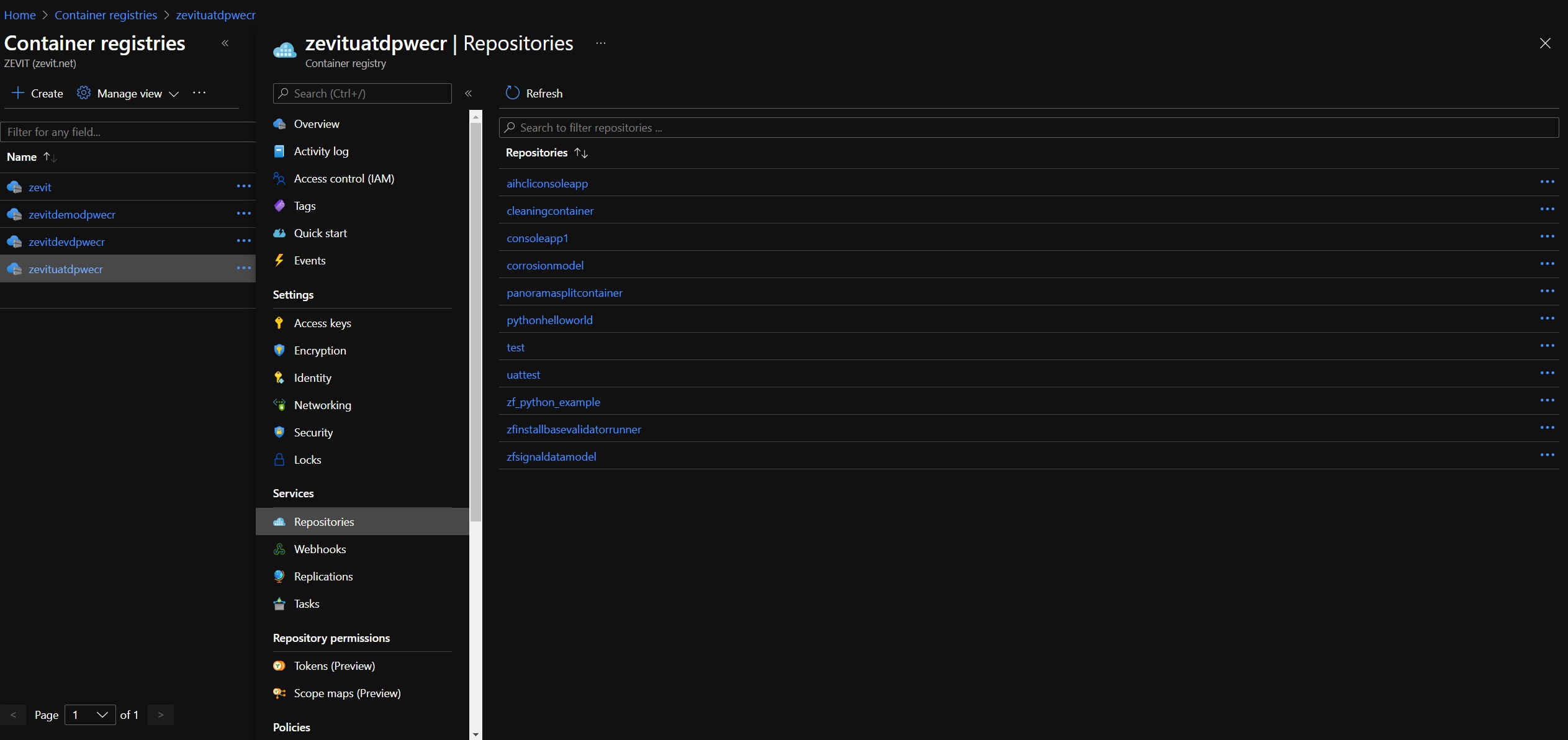
To find which models are defined in ACI the user needs to call the endpoint GET \JobDefinitions
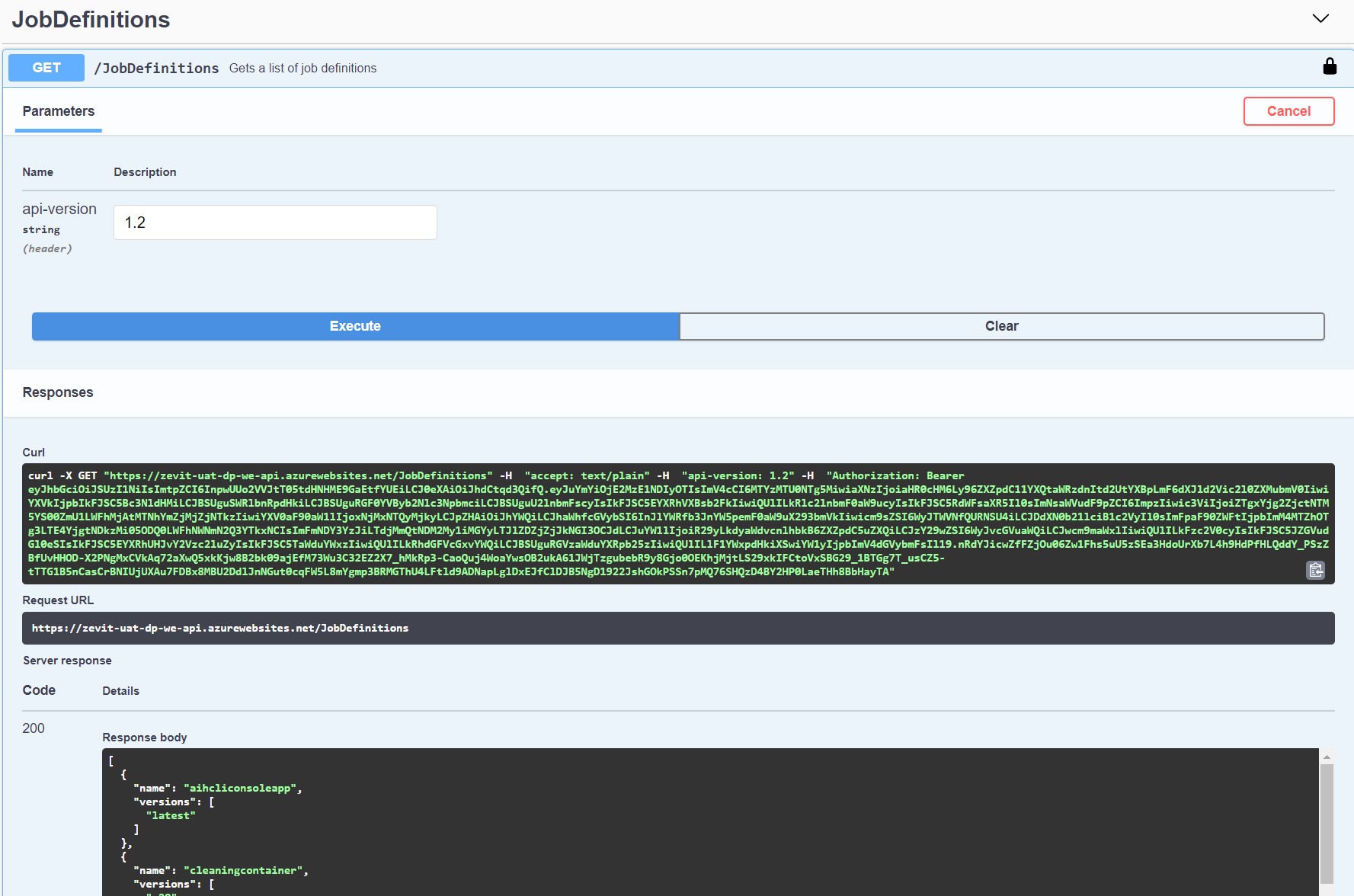
Jobs are the running stage of the given job configuration, hence the jobs are are the containers and job configs are the images.
Versioning of DP API#
Note: DP API v1.0 and v1.1 were removed.
v1.2#
DP API v1.2 version uses Azure Container Instances(ACI) service.
Azure Container Instances is a service that enables to deploy containers on the Microsoft Azure public cloud without having to provision or manage any underlying infrastructure.
ACI docs - https://docs.microsoft.com/en-us/azure/container-instances/container-instances-overview
ACI pricing - https://azure.microsoft.com/en-us/pricing/details/container-instances/
Important
At this time, deployments with GPU resources are not supported in an Azure virtual network deployment and are only available on Linux container groups.
Container groups docs - https://docs.microsoft.com/en-us/azure/container-instances/container-instances-region-availability#linux-container-groups
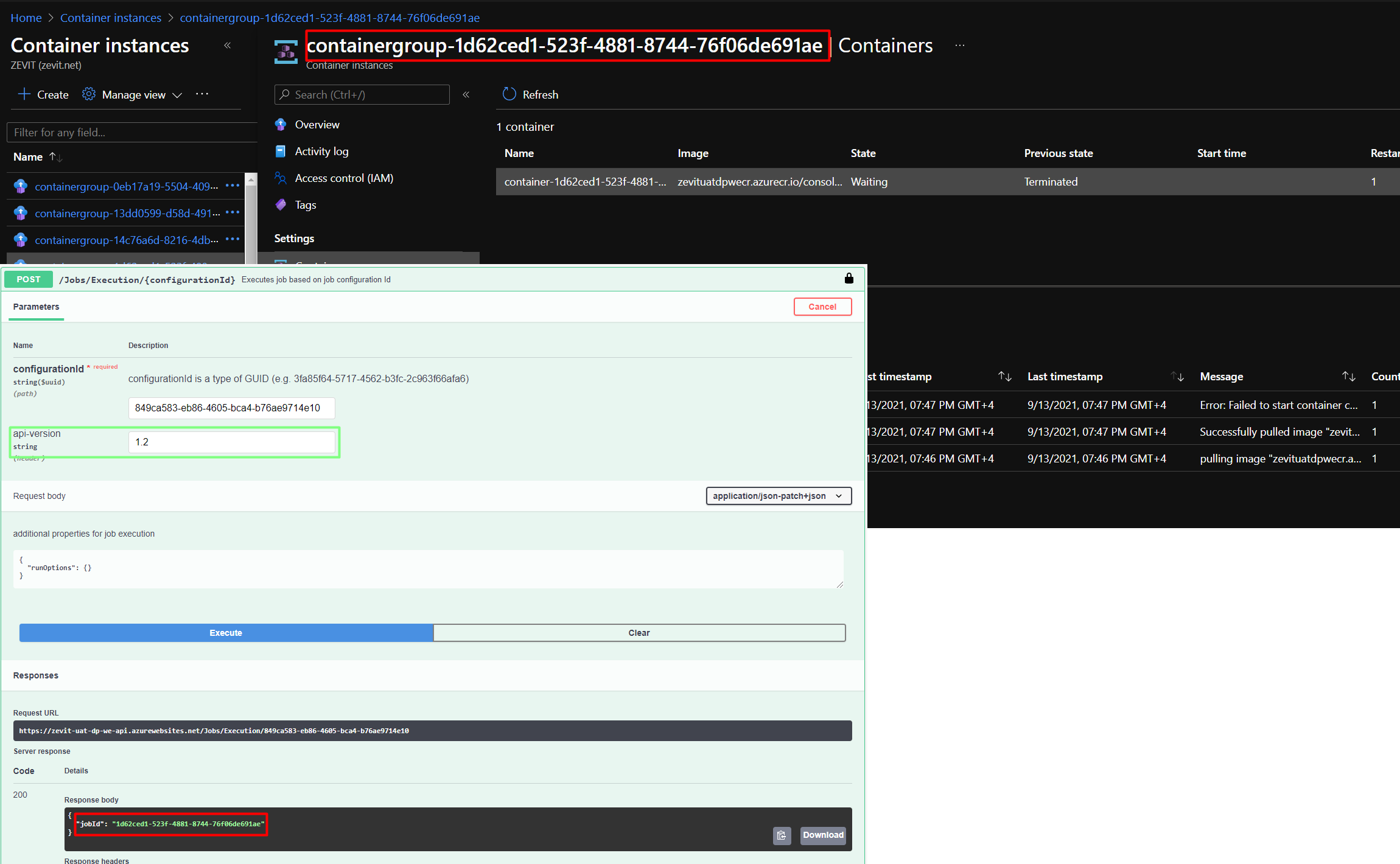
This means that Job Configs will run Jobs in the ACR. Here, when the user executes the job with job config id (using POST /Jobs/Execution/{configurationId}) the API creates a new container group, which name is formed as "containergroup-{jobId}".
Benefits#
- The user pays only while the container is running. Azure Container Instances have a per-second billing model
- ACI provides a separate resource for each job. The user does need to wait for the other jobs to finish.
- The user can specify VM parameters per job (CPU or GPU sizes can be specified in the configs of the container).
Run Configs#
For V1.2 Job config also has a run config.
{ "runConfigs": { "cpuCores": 1, "memory": 1, "gpuCores": null, "gpusku": null }}Run Options#
Job config's run options field is JSON type and it is for declaring environment variables that will be passed to the job after execution. It means that from executed job user can get all ENV variables and find ones that he has declared.
Example:
{ "runOptions": { "key1": "value1", "key2": "value2" }}POST /Jobs/Execution/{configurationId} endpoint also takes run options as a body. Those parameters will be merged with job configs run options(if they exist) and passed to the job. Note that the jobs run options have more priority.
Example:
Job Config -
{ "runOptions": { "key1": "valueFromConfig", "key2": "value2" }}Job Execution body-
{ "runOptions": { "key1": "valueFromJob", "key3": "value3" }}To the job will be passed those run options
{ "runOptions": { "key1": "valueFromJob", "key3": "value3", "key2": "value2", "jobId": "{Id of current job}" }}For jobId see default run options
When job config has a next config id and the user executes it with run options (as a request body) the system will pass request body run options only to the first job. For the next chain items system will take only job config's run options.
Default run options#
When executing a job the system automatically passes job id as an environment variable to the job where key = "jobId"
Encription#
In the database run options are stored as an encrypted text. The system uses the symmetric-key hashing algorithm. The encryption key is stored in key vaults with the "dataprocessing-encryption-key" name.
Chaining the Job configs#
Job configuration has a nextConfigId property, which links job configs and allows to run them as a linked job configs chain.
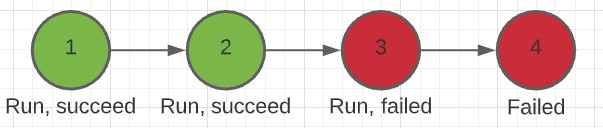
Here, the nextConfigId of 1 is 2, 2's nextConfigId is 3 and so on.
When the user executes the Job with job config 1 the DP will create 4 new jobs and start the execution of the first one. If the job fails (e.g. 3) the system will fail the next one(s). (e.g.., 4).
Job configs can also be scheduled (See scheduling jobs). When the user specifies the schedule, the system runs the whole chain with the given frequency.
If the user wants to chain few job configs only for one-time usage (without modifying the job config), POST /Jobs/ChainExecution endpoint can be used. Here as a body user can specify jobConfigIds, order of its execution, and run options for each job config.
Run Command#
Job config's run command field is for specifying commands which will be executed on a given definition. Jobs execution will start with the given command.
Job statuses#
Jobs have a status field which is the current state of jobs.
- Unknown - The status of a job is unknown
- Started - Job was created in the database but not runned yet
- InProgress - a job is still running
- Failed - the job was failed while running. The reason for failure is written in the "error message" field of the job.
- Success - the job was successfully runned
Job's output field#
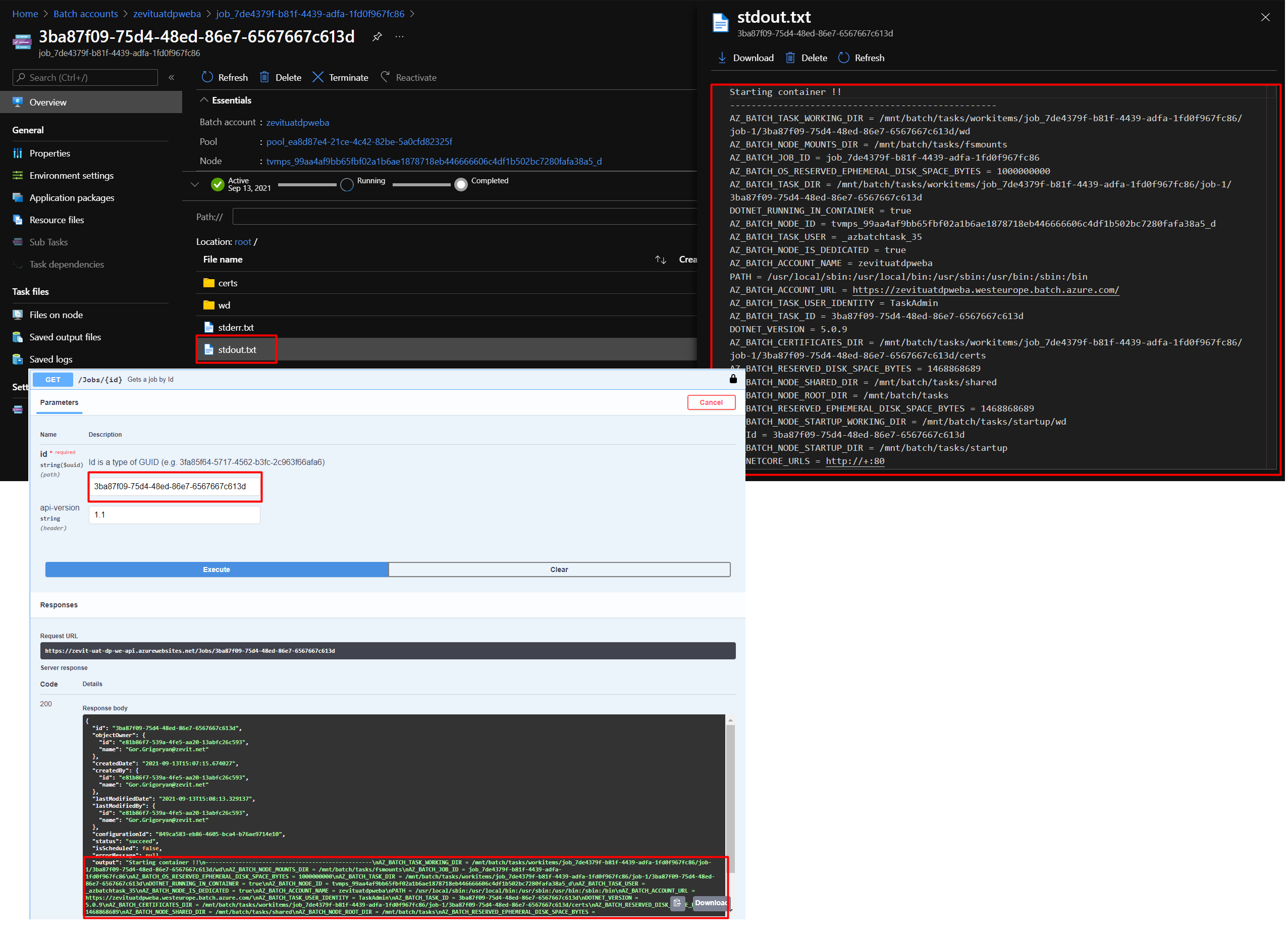
When job config runs and turns to job/task, the user can see outputs of the container inside batch account/ACI and job DTO via GET \Jobs\{Id} endpoint. DP API updates Job's output field each minute. It takes the output from the running container. When job execution is finished DP API deletes its instance from Azure. Users can find old runned jobs from an API.
Scheduling Jobs#
DP API also allows scheduling jobs and running them with frequency. For scheduling jobs, we need to specify the frequency of job config.
Example:
{ "frequency": { "dayOfWeek": "wednesday", "hour": 21, "startDate": "2021-08-24T11:42:00" }}Here job config will start execution in 2021-08-24T11:42:00 and will run each Wednesday at 21.00
When the user executes the job, DP API will each time create a new job with the scheduled job configs and run it. The job running logic/technology will then depend on the API version in use.
Job Output and Output Type#
Job output is an entity for storing data after jobs execution. JobOutput must have a link to the job output type. It also has an output field which is JSON, where an output of any structure can be stored.
The output type is a way of sorting and validating outputs. OutputType has a Schema field, which must be of json schema.
Example:
{ "type": "object", "properties": { "fileId": { "type": "string", "format": "uuid" }, "rowNumber": { "type": "number" } }, "additionalProperties": false}This JSON schema says that our JSON must be an object, it can have only fileId and rowNumber. FileId must be UUID (e.g. 538a2c39-b931-4798-ad0d-68d75151f4b1) and rowNumber must be a number.
So, the output will be like this:
{ "fileId": "538a2c39-b931-4798-ad0d-68d75151f4b1", "rowNumber": 6}Schema property is not required, it means that if the user wants to have unstructured outputs, they can just leave schema null. However, please note that if the output is not similar to the output type schema, the system will not create any entity.